# Making Instagram.com faster: Part 2
# 让 Instagram.com 变得更快: 第二章
In recent years, instagram.com has seen a lot of changes — we’ve launched stories, filters, creation tools, notifications, and direct messaging as well as myriad other features and enhancements. However, as the product grew, one unfortunate side effect was that our web performance began to suffer. Over the last year, we made a conscious effort to improve this. Our ongoing efforts have thus far resulted in almost 50% cumulative improvement to our feed page load time. This series of blog posts will outline some of the work we’ve done that led to these improvements.
最近这几年,instagram.com 改版了很多 - 我们在 INS 中加入了 Stories、滤镜、创作工具、系统通知和消息推送等新特性和功能增强。然而,伴随着产品的不断迭代成长,一个不幸的事情发生了:我们的 web 端性能开始下降了。为处理性能下降,在最近的一年中,我们有意识地开展一些工作来提升性能。截止目前,我们的不懈努力已经让 Feed 页面加载时间减少了将近 50%。这个系列的博客文章将会讲述我们为实现这些提升所做的一些工作。
译注:和第一章的摘要一样,看过的可以忽略
# Pushing data using early flushing and progressive HTML
# 使用early flush(提前刷新)和progressive HTML(渐进式HTML)来推送数据
In part 1, we showed how using link preloads allows us to start dynamic queries earlier in the page load i.e. before the script that will initiate the request has even loaded. With that said, issuing these requests as a preload still means that the query will not begin until the HTML page has begun rendering on the client, which means the query cannot start until 2 network roundtrips have completed (plus however long it takes to generate the html response on the server). As we can see below for a preloaded GraphQL query, even though it’s one of the first things we preload in the HTML head, it can still be a significant amount of time before the query actually begins.
在第一章中,我们展示了如何使用link预加载,它使得页面能够在更早阶段,就开始动态查询(在逻辑JS加载之前)。然而,即便为这些动态查询加上了预加载处理,仍然需要等到HTML页面在客户端开始渲染后,这些动态查询才开始(预)加载。这意味着:需要等2个网络往返完成,查询才能开始(还要加上服务器响应请求生成html所需的时间)。正如在下图中我们看到的预加载GraphQL请求一样:尽管这是在 HTML head 中标记预加载的第一批内容,但实际上要等上很长时间,查询才能真正开始。
译注:这里2个网络往返,指html的请求和响应,服务器生成html的时间可能会很长

The theoretical ideal is that we would want a preloaded query to begin execution as soon as the request for the page hits the server. But how can you get the browser to request something before it has even received any HTML back from the server? The answer is to push the resource from the server to the browser, and while it might look like HTTP/2 push is the solution here, there is actually a very old (and often overlooked) technique for doing this that has universal browser support and doesn’t have any of the infrastructural complexities of implementing HTTP/2 push. Facebook has been using this successfully since 2010 (see BigPipe), as have other sites in various forms such as Ebay — but this technique seems to be largely ignored or unused by developers of JavaScript SPAs. It goes by a few names — early flush, head flushing, progressive HTML — and it works by combining two things:
我们希望的理想效果是,预加载查询在页面请求到达服务端时就开始执行。但问题是如何让浏览器还没有任何服务端的html返回,就发起请求呢?答案是服务器主动向浏览器推送资源,这看上去有点像利用HTTP/2的push特性,但实际上用的是一种非常古老的技术(也通常被忽视的),它具有非常好的浏览器兼容性,并且不需要为实现HTTP/2的push特性而增加服务端基础架构的复杂性。Facebook在2010年就成功应用这项技术(详情见 BigPipe),还有其它各种网站的实践案例(比如Ebay)- 但是很多JavaScript开发人员似乎忽略了该技术或未使用该技术,特别是在SPA架构的网站中。那么这项技术到底叫什么呢?它有着好几个名称 - early flush(提前刷新)、head flushing(头部刷新)、progressive HTML(渐进式渲染HTML)。它的主要实现包含两点:
HTTP chunked transfer encoding
Progressive HTML rendering in the browser
HTTP 分块传输编码
浏览器渐进式渲染HTML
译注:flush,这个单词思来想去,从前端的角度都不是很好翻译,如果有大佬知道请指教。
查询相关文章,flush最早是后端开发中的概念,比如jsp或者php生成html的时候,可以分段生成,调用类似flush命名的api,生成一小段先返回客户端。所以个人理解flush大致的意思是:将内容刷到某个载体上,在这里指将代码刷到html中?
Facebook在BigPipe的实现中,核心思路也就是分步 flush 内容到浏览器,中文方面可以阅读这篇文章:高性能WEB开发(11) - flush让页面分块,逐步呈现
Chunked transfer encoding was added as part of HTTP/1.1, and essentially it allows an HTTP network response to be broken up into multiple ‘chunks’ which can be streamed to the browser. The browser then stitches these chunks together as they arrive into a final completed response. While this does involve a fairly significant change to how pages are rendered on the server side, most languages and frameworks have support for rendering chunked responses (in the case of Instagram we use Django on our web frontends, so we use the StreamingHttpResponse object). The reason this is useful is that it allows us to stream the contents of an HTML page to the browser as each part of the page completes — rather than having to wait for the whole response. This means we can flush the HTML head to the browser almost immediately (hence the term ‘early flush’) as it doesn’t involve much server-side processing. This allows the browser to start downloading scripts and stylesheets while the server is busy generating the dynamic data in the rest of the page. You can see the effect of this below.
Chunked transfer encoding(分块传输编码)是HTTP/1.1协议中的一部分,从本质上来看,它允许服务端将HTTP的返回切碎成多个chunk(块),然后以分流的形式传输给浏览器。浏览器不断接收这些块,然后在最后一个块到达后将它们聚合在一起。这种做法看上去需要对 服务端生成HTML 做很大的改造,但实际上大部分的语言和框架都已经支持分块生成返回(在INS中,web框架是Django,因此采用 StreamingHttpResponse 对象来实现)。
那么回到正题,这种做法是如何让预加载的更早地开始呢?因为它允许服务器在完成每个chunk时,就将此时的HTML页面的内容流式传输到浏览器,而不必等待整个HTML完成。这意味服务器一收到请求,就可以将HTML的头部flush给浏览器(所以被称为 early flush),减少了处理HTML剩余内容(比如Body内DOM)的时间。而对于浏览器来说,浏览器在收到HTML的头部时,就可以开始预加载静态资源和动态数据,此时服务器还在忙于剩余HTML内容的生成。可以查看下面两张图来比较优化效果:
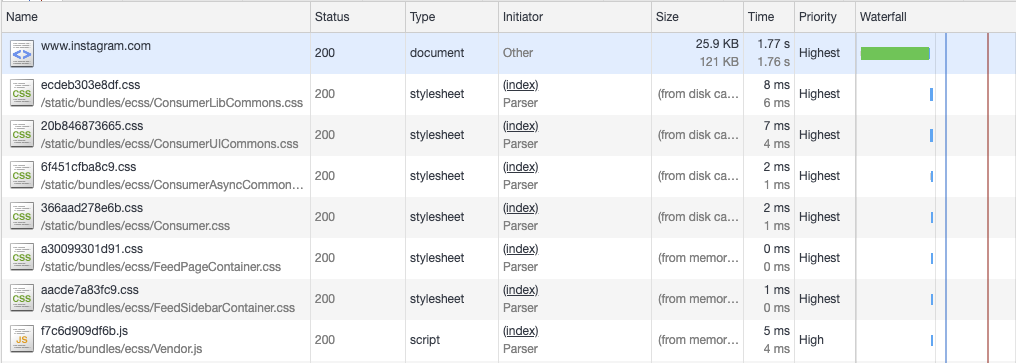
- 默认: 等到HTML下载完成,资源才开始加载
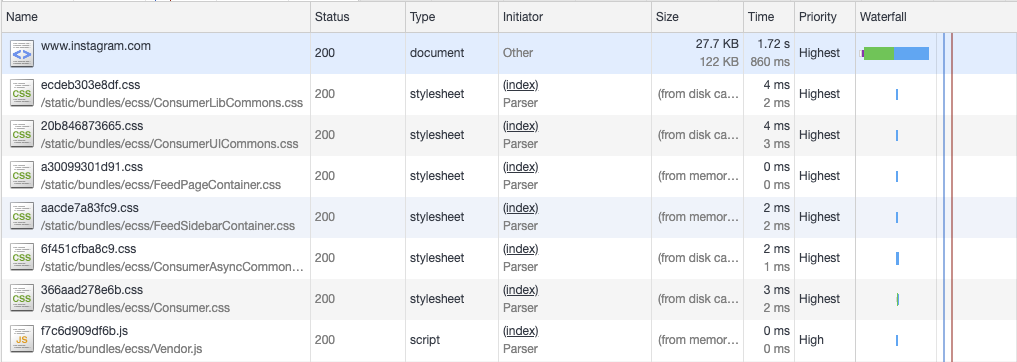
- 有early flush: 当HTML第一次fulshed到浏览器时,资源就开始加载
译注:试了下这个应该是在Fast 3G下的测试结果,减少了一半的时间(约800ms)
Additionally, we can use chunked encoding to send data to the client as it completes. In the case of server-side rendered applications this could be in the form of HTML, but we can push JSON data to the browser in the case of single page apps like instagram.com. To see how this works, let’s look at the naive case of a single page app starting up. First the initial HTML containing the JavaScript required to render the page is flushed to the browser. Once that script parses and executes, it will then execute an XHR query which fetches the initial data needed to bootstrap the page.
另外,我们可以利用 「分块传输编码」 在传输完成的同时将其它数据推送到客户端。对于服务端渲染的Web应用,一般采用HTML格式返回;对于诸如instagram.com的SPA,可以用JSON格式数据推送到浏览器。为了解其工作原理,让我们看一下SPA一般的启动过程。首先,服务端将包含首次渲染页面所需的JS的HTML刷新(flush)到浏览器。这个JS解析并执行后,再执行XHR查询,然后XHR查询返回引导页面所需的初始数据(如下图所示)。
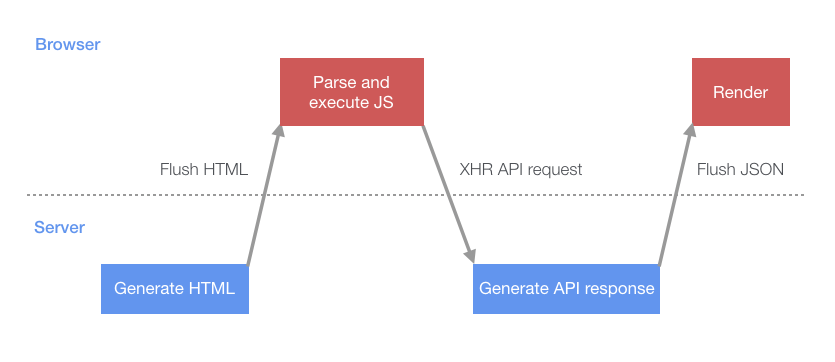
This process involves multiple roundtrips between the server and client and introduces periods where both the server and client are sitting idle. Rather than have the server wait for the client to request the API response, a more efficient approach would be for the server to start working on generating the API response immediately after the HTML has been generated and to push it to the client. This would mean that by the time the client has started up the data would likely be ready without having to wait for another round trip. The first step in making this change was to create a JSON cache to store the server responses. We implemented this by using a small inline script block in the page HTML that acts as a cache & lists the queries that will be added to this cache by the server (this is shown in a simplified form below).
服务端和客户端在这个过程中进行了多次数据往返,并且都有大量空闲时间,这显然可以进行优化。从效率上看,比起让服务端等待客户端发起某个API请求,不如让服务端在生成初始化HTML推送给客户端后,就开始生成某个API要返回的数据。这意味着,客户端启动查询的时候,服务端的数据可能已经准备好并推送到客户端了,这样就不需要额外的网络请求开销。这个改动的第一步是:创建1个JSON缓存对象来存储服务端返回的数据。代码写在HTML中一小段内联脚本中,它充当缓存的角色,并且会列出所有服务端将要推数据缓存的请求(下面是简化的代码示例)。
<script type="text/javascript">
// the server will write out the paths of any API calls it plans to
// run server-side so the client knows to wait for the server, rather
// than doing its own XHR request for the data
// 服务端将会写下所有它已经在准备的请求的路径,这样客户端就知道等待服务端返回数据就行,而不需要自己发起XHR请求
window.__data = {
'/my/api/path': {
// 客户端发起请求后的回调都存在waiting数组中
waiting: [],
}
};
window.__dataLoaded = function(path, data) {
const cacheEntry = window.__data[path];
if (cacheEntry) {
cacheEntry.data = data;
for (var i = 0;i < cacheEntry.waiting.length; ++i) {
cacheEntry.waiting[i].resolve(cacheEntry.data);
}
cacheEntry.waiting = [];
}
};
</script>
After flushing the HTML to the browser the server can execute the API query itself and when it completes, flush the JSON data to the page as a script tag containing the data. When this HTML response chunk is received and parsed by the browser, it will result in the data being inserted into the JSON cache. A key thing to note with this approach is that the browser will render progressively as it receives response chunks (i.e. they will execute complete script blocks as they are streamed in). So you could potentially generate lots of data in parallel on the server and flush each response in its own script block as it becomes ready for immediate execution on the client. This is the basic idea behind Facebooks BigPipe system where multiple independent Pagelets are loaded in parallel on the server and pushed to the client in the order they complete.
在把HTML刷新到浏览器之后,服务端就可以自己执行API请求的查询,完成后将JSON数据以「包含script标签的HTML片段」的形式刷新到页面中。当这个HTML片段被浏览器接收并解析后,它会将数据写入JSON缓存对象中。这里有个关键技术点是:浏览器会在接收到chunks的时候就立即开始渲染(类似的,也会立即执行script标签中的JS代码块)。所以,你甚至可以在服务端并行生成一系列API数据,并在每个API数据准备好时,就立即将其刷新到JS块中。这是Facebook BigPipe系统背后的基本思想,在这个系统中,多个独立的「Pagelet」 并行到服务器上加载,并按它们完成的顺序依次推送到客户端。
译注:Pagelet是BigPipe技术中的词汇,HTML片段的意思,一个基本的 pagelet 包含了 id 、 HTML片段 、 依赖的CSS 、JavaScript 资源。Github地址:https://github.com/bigpipe,中文方面的文章可以参考Pagelet的前世今生
<script type="text/javascript">
window.__dataLoaded('/my/api/path', {
// API json response, wrapped in the function call to
// add it to the JSON cache...
// API返回的JSON,包在 window.__dataLoaded 的函数参数中,将插入上面例子中的JSON缓存对象 window.__data
});
</script>
When the client script is ready to request its data, instead of issuing an XHR request, it first checks the JSON cache. If a response is present (or pending) it either responds immediately, or waits for the pending response.
当客户端JS准备好请求某个特定数据的时候,它将先检查JSON缓存对象中有没有数据,而不是发起一个XHR请求。如果JSON缓存对象中已经有数据,它将立即得到返回;如果JSON缓存对象是经标记了pending,它将把请求的resolve回调注册到对应的waiting数组中,请求完成后,执行对应的resolve回调。
function queryAPI(path) {
const cacheEntry = window.__data[path];
if (!cacheEntry) {
// issue a normal XHR API request
// 兜底,没有缓存对象,直接发起一个普通的XHR请求
return fetch(path);
} else if (cacheEntry.data) {
// the server has pushed us the data already
// 服务端已经推送好数据了
return Promise.resolve(cacheEntry.data);
} else {
// the server is still pushing the data
// so we'll put ourselves in the queue to
// be notified when its ready
// 服务端正在生成数据或推送中
// 我们把请求成功的resolve回调放到cacheEntry.waiting队列中
// 当接收到数据后,回调会按顺序执行
const waiting = {};
cacheEntry.waiting.push(waiting);
return new Promise((resolve) => {
waiting.resolve = resolve;
});
}
}
This has the effect of changing the page load behavior to this:
这就把浏览器的页面加载行为改成下面的模式了:
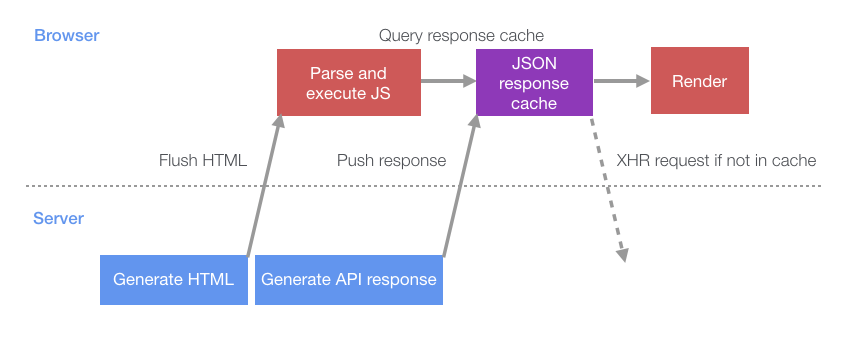
Compared to the naive loading approach, the server and client can now do more work in parallel — reducing idle periods where the server and client are waiting on each other. The impact of this was significant: desktop users experienced a 14% improvement in page display completion time, while mobile users (with higher network latencies) experienced a more pronounced 23% improvement.
相比于最初的加载流程,优化后的服务端和客户端可以并行地进行更多的工作 - 减少因为相互等待返回造成的空间时长。此项优化的效果非常明显:桌面端用户访问页面的渲染完成的时间减少了14%,移动端用户(有更高的网络的延迟)更是减少了23%。
译注:并行的更多工作可以这么理解:对于服务端来说,是边生成数据边返回,对于浏览器来说,是边接收数据边渲染页面
# Stay tuned for part 3
# 请继续关注第三章
In part 3 we’ll cover how we further improved performance by taking a cache first approach to rendering data. If you want to learn more about this work or are interested joining one of our engineering teams, please visit our careers page, follow us on Facebook or on Twitter.
在第3部分中,我们将介绍如何采用缓存优先的方式来渲染数据,从而进一步提高性能。 如果您想了解更多有关这项工作的信息,或者有兴趣加入我们的团队,请访问我们的公司岗位页面,也可以关注我们on Facebook或者on Twitter。